Aerial Cactus Identification Kaggle

Hello World !!!
In my quest of learning Computer vision I am starting with small datasets and less complex problems. So, today I am trying my hands on a kaggle problem which is basically an Image Classification problem from Kaggle
pls visit github for jupyter notebook
Description
To assess the impact of climate change on Earth’s flora and fauna, it is vital to quantify how human activities such as logging, mining, and agriculture are impacting our protected natural areas. Researchers in Mexico have created the VIGIA project, which aims to build a system for autonomous surveillance of protected areas. A first step in such an effort is the ability to recognize the vegetation inside the protected areas. In this competition, you are tasked with creation of an algorithm that can identify a specific type of cactus in aerial imagery.
Evaluation
Submissions are evaluated on area under the ROC curve between the predicted probability and the observed target.
Data
This dataset contains a large number of 32 x 32 thumbnail images containing aerial photos of a columnar cactus (Neobuxbaumia tetetzo). Kaggle has resized the images from the original dataset to make them uniform in size. The file name of an image corresponds to its id.
We must create a classifier capable of predicting whether an images contains a cactus.
Files
- train/ - the training set images
- test/ - the test set images (you must predict the labels of these)
- train.csv - the training set labels, indicates whether the image has a cactus (has_cactus = 1)
- sample_submission.csv - a sample submission file in the correct format
Approach
We will not be using any pretrained model this time and will rather create a model from scratch for learning purpose.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn, gc, time, os, math
from sklearn.model_selection import train_test_split
import tensorflow as tf
print(tf.__version__)
from tensorflow.keras.preprocessing.image import load_img, ImageDataGenerator
seed = 42
np.random.seed(seed)
tf.random.set_seed(seed)
2.3.0
load the data
We have been given two folders for train and test images which contain images for both positive and negative classes. First we load the .csv file which has the IDs of images and their labels.
visualize the data
The first thing to do in Machine Learning is to understand the data yourself before fitting any model. It is better to understand the data and have a good intuition about the features(e.g. in case of tabular data) which may help in curve fitting and later interpreting the model. In our case we will pick randomly few samples and see the distribution of positive(image has cactus) and negative(image does not have cactus) classes.
fig,ax = plt.subplots(2,5, figsize=(10,7))
for i, index in enumerate(train_df[train_df["has_cactus"] == 1]["id"][:5]):
path = os.path.join(train_dir, index)
img = load_img(path)
ax[0,i].set_title("Cactus")
ax[0,i].imshow(img)
for i, index in enumerate(train_df[train_df["has_cactus"] == 0]["id"][:5]):
path = os.path.join(train_dir, index)
img = load_img(path)
ax[1,i].set_title("No Cactus")
ax[1,i].imshow(img)

split the data into train and val
Next we will create a validation split to evaluate our training on train dataset.
print("before split train shape", train_df.shape)
train_df, val_df = train_test_split(train_df, test_size=0.2, stratify=train_df["has_cactus"], shuffle=True, random_state=seed)
train_df = train_df.reset_index(drop=True)
val_df = val_df.reset_index(drop=True)
print("after split train/val shape", train_df.shape, val_df.shape)
before split train shape (17500, 2)
after split train/val shape (14000, 2) (3500, 2)
prepare data for modeling
Loading the data using TensorFLow/Keras API from a folder where images of all the classes are clubbed into one folder. I mean there is no subfolder for each class. So, we will be using ImageDataGenerator class which generates batches of tensor images with real-time data augmentation. From this class we will be using flow_from_dataframe method which will help us map image IDs to their respective images from the directory and generates batches of images.
We will only be rescaling and not perform any other augmentation on images.
img_width, img_height = 32,32
target_size = (img_width, img_height)
batch_size = 32
train_datagen = ImageDataGenerator(rescale=1./255)
val_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_dataframe(dataframe=train_df,
directory=train_dir,
x_col='id',
y_col='has_cactus',
target_size=target_size,
class_mode='binary',
batch_size=batch_size,
seed = seed)
val_generator = val_datagen.flow_from_dataframe(dataframe=val_df,
directory=train_dir,
x_col='id',
y_col='has_cactus',
target_size=target_size,
class_mode='binary',
batch_size=batch_size,
seed = seed)
Found 14000 validated image filenames belonging to 2 classes.
Found 3500 validated image filenames belonging to 2 classes.
creating a CNN model from scratch
Creating a model from scratch may not be a good idea always. There aren’t much samples available all the time for us to fully exploit(converge) a complex model without overfitting. Someone (maybe a research institute, tech giants etc.) might have worked on a similar problem and might have trained a huge model for multiple epochs and done a finetuning and later open-sourced the weights of that model. So, it’s a good idea to create a model from scratch and use it as a base model and then use a pretrained model to get better on the measure of success.
We will be creating a simple Convolutional Neural Networks(CNN) model using keras layers and its functional API for Models. We will be using Adam (with its default learningRate=0.001)as the optimizer, binary_crossentropy as loss and AUC as metrics. For Callbacks we have used LearningRateScheduler for learning rate decay and EarlyStopping in case the val_loss doesn’t improve. Running it for 20 epochs should be a good start.
inputs = Input(shape=(*target_size, 3))
x = Conv2D(32, (3,3), activation='relu')(inputs)
x = MaxPool2D((2,2))(x)
x = Dropout(0.25)(x)
x = Conv2D(64, (3,3), activation='relu')(x)
x = MaxPool2D((2,2))(x)
x = Dropout(0.25)(x)
x = Conv2D(128, (3,3), activation='relu')(x)
x = MaxPool2D((2,2))(x)
x = Dropout(0.25)(x)
x = GlobalMaxPool2D()(x)
x = Dense(128, activation='relu')(x)
x = Dropout(0.25)(x)
outputs = Dense(1, activation='sigmoid')(x)
model = Model(inputs, outputs)
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['AUC'])
model.summary()
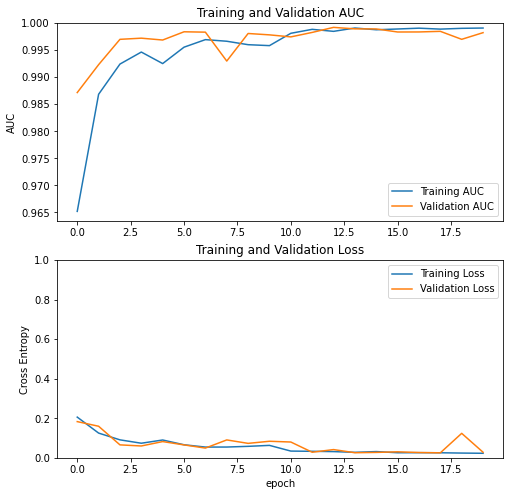
visualize learning curve
A very useful piece of code to visualize the learnign curves from tensorflow
acc = history.history['auc']
val_acc = history.history['val_auc']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training AUC')
plt.plot(val_acc, label='Validation AUC')
plt.legend(loc='lower right')
plt.ylabel('AUC')
plt.ylim([min(plt.ylim()),1])
plt.title('Training and Validation AUC')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.ylim([0,1.0])
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
prediction on test data
test_df = pd.read_csv("sample_submission.csv")
test_dir = '/cp/kaggle/aerial-cactus-identification/test'
test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_directory(directory=test_dir,
target_size=target_size,
class_mode='binary',
batch_size=1,
shuffle=False,
seed=seed)
Found 4000 images belonging to 1 classes.
# predict on test images
preds = model.predict(test_generator)
test_df["has_cactus"] = preds
Learnings
- How to load the data using TensorFLow/Keras from a directory of images.
- How to visualize the data.
- How to prepare data for augmentation.
- How to write CNN model from scratch using functional API of keras Model.
- How to visualize accuracy/loss learning curves for train/val data.